




Speech synthesis is the production of human speech, artificially.
Speech Synthesis has been a vital part of artificial Intelligence and is embedded in almost every device out there today. Most our smartphones & PCs can interact directly with us by using a technology called Speech synthesizer, which has been of great assistance to those with visual disabilities. The technology helps them to understand better, by reading out messages and other functionalities.
Definition of Speech Synthesis.
Speech synthesis is the production of a computer-generated simulation of human speech, it takes texts as input and output voice for convenient use, in areas such as reading out email messages, chat by those who are visually impaired.
Speech synthesis can also be referred to as text-to-speech (TTS), which converts normal language text into speech; and the opposite is voice recognition.
Why do we need Speech Synthesis?
In the 21st century, talking computers are not near to anything new, but having one interact efficiently with the user is very rare. Yes! we listen to automated response from network operators, but hardly can you find one you can easily interact with. But for Artificial Intelligence to move a great deal we need to perfect the art of speech synthesis and voice recognition.
Mark Zuckerberg had a vision in 2016, and that was to build a simple AI to run his home — like Jarvis in Iron Man. He recently posted a note on Facebook, and he talked a great deal about the use of Speech Synthesis and voice recognition in building his new AI agent.

Mark can order his new AI to switch off the light via text of voice.
So far this year, I’ve built a simple AI that I can talk to on my phone and computer, that can control my home, including lights, temperature, appliances, music and security, that learns my tastes and patterns, that can learn new words and concepts, and that can even entertain Max. It uses several artificial intelligence techniques, including natural language processing, speech recognition, face recognition, and reinforcement learning, written in Python, PHP and Objective C. In this note, I’ll explain what I built and what I learned along the way – Mark Zuckerberg
The quality is determined by how similar & interactive the produced voice is to human. Many computers operating system have included speech synthesizers since the early 1990s.
How does speech synthesis work?
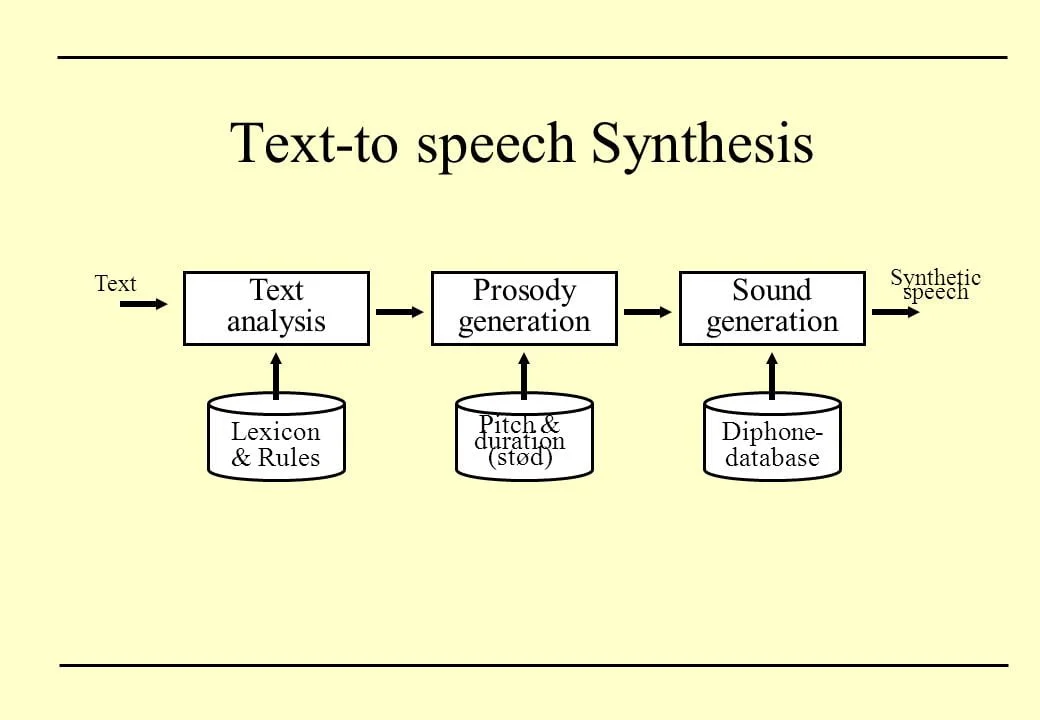
So, there is a little text you want your computer or smartphone to read out aloud- Then you start thinking how does speech synthesis work? Speech synthesis follows three different processes which can be called text -> words, words -> phonemes, and phonemes -> sound.
During the first stage of text -> words, the computer tries to understand the meaning of the text written down, all the characters need to be turned to reasonable words that can be understood. This might seem easy for humans but not computers. The term ‘1956’ can be referred to year, passcode to a lock, numbers or quantity of an item- the computer must be able to differentiate easily the most appropriate.
In this stage also the computer must perfect the pronunciations & be able to differentiate similar texts used so as to be efficient in its final output, E.g reed, read, red, rid, heed.
The next stage is words -> phonemes, after the computer has finished processing the words to be said, it now need to be able to produce the perfect sound to those words. The computer then uses the alphabets and the pronunciations( which is what is called phonemes).
The process involved here is a little more detailed but in layman understanding, this should do.
You can read more on phonemes here.
The last stage is phonemes -> sounds
Now we have the phonemes of the texts, but it still needs to be spoken out in a tone which is where this stage comes in. The easiest way to get that voice is to find people to record different phonemes and store them locally so that the computer can easily play the stored phonemes of the text entered.
Want to test Speech synthesis on your Windows PC?
If you have a Windows computer somewhere, you can test speech synthesis on it.
The built-in text-to-speech program is called Narrator:
- Windows XP: Find Narrator from the Start menu like this:
Start > Programs > Accessories > Accessibility > Narrator - Windows Vista: There’s a very similar but better-sounding version of Narrator:
Start > Programs > Accessories > Ease of Access > Narrator.





